Introduction
Hello, my name's Carol Geng, a current sophomore pursuing a Bachelor's degree in Computer Science at Texas A&M University. Over Summer 2022, I have contributed to Tremor as part of the LFX Mentorship Program with my mentors Heinz Gies and Matthias Wahl, and this blog will show how valuable and enjoyable the experience was.
About the Project
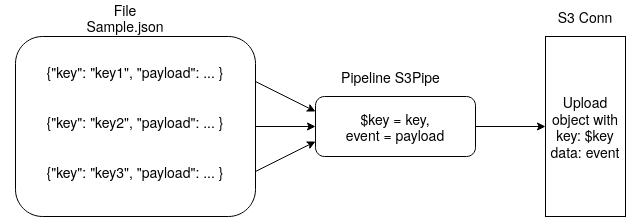
Tremor is an event processing engine that uses pipelines and connectors for data to be passed through. However, errors could be made by the user when linking the ports of the pipelines, and those errors are not easily displayed to the user. There were cases where the location of the error wasn’t printed, nothing was printed at all, or even cases where the program would work as if everything was all fine. My mentorship project was focused on creating the messages that would be displayed to the user in a clear and concise manner through the console.
The Mentorship Journey
Before this mentorship, I had only worked in open-source a few times on projects and had no knowledge of how to code in Rust. This mentorship therefore allowed me to build on what I already knew while also giving me an opportunity to learn a new language. Throughout this mentorship, I was able to get a start in DevOps and learn how to work on the compiler and source code for a software program while contributing to the user experience of everyone who uses Tremor and whoever will use Tremor in the future.
Starting Tremor
To learn how to contribute to Tremor’s source code, I had to first understand how Tremor worked and what it did. I was introduced to pipelines, ports, and scripts and was allowed to mess around with the code. Tremor’s code allowed the user to go into several commands to process and change the input into the desired output. Through playing around with Tremor, I decided to add a function to reverse a string with Tremor’s pipelines. Because tremor did not have a built-in reverse string function, I went into the source code to implement a reverse function in Rust along with several tests and documentation for the reverse function. This relatively simple function is where I made my first pull request and also where I first started getting familiar with Tremor.
Additionally, I had used other programming languages in my academic career, and therefore did not have any experience with Rust beforehand. This is when I got introduced to Rustlings, which had small exercises to help me with starting with Rust syntax and writing code in Rust. There were also a lot of functions unique to Rust in terms of how the code worked, which included enums, move semantics, and structs. This also included constructs like Ok() and concepts like async/await which I would end up utilizing in my project.
Understanding Code
A large portion of my mentorship focused on understanding the errors that were printed out. There were several different kinds of errors, such as ones that dealt with the console input, console output, pipeline input, and more, which validated whether the input or output existed in the code and where it led to, another connector or the console. While this may seem simple, this ended up leading me into the rabbit hole of the source code as I traversed through numerous files and functions to determine where the error went through and what I could do to the preexisting code to read and perform functions onto the error.
To do a lot of this, I learned the process of error logging. I defined each error there in great detail, such as what it is, what it does currently, what it’s supposed to do, and gradually updated it every time it was needed. Throughout implementing messages to these errors, I also learned more about version control with git. While I did have practice on the basics like git pull and git push, I also learned about git rebase, git merge, and more.
Error Handling
Error handling was the main focus of the project. As my mentor suggested, I focused on one error at a time from the error logs. First, I focused on the worst case- a case where nothing was printed and the program ran as if everything was normal, except there was no output.
pipeline_out_error.troy
# Our main flow
define flow main
flow
# import the `tremor::connectors` module
use tremor::connectors;
use lib::pipelines;
# create an instance of the console connector
create connector console from connectors::console;
# create an instance of the passthrough pipeline
create pipeline main from pipelines::main;
# connect the console (STDIN) to our pipeline input
connect /connector/console/out to /pipeline/main;
# then connect the pipeline output to the console (STDOUT)
# no doesn't exist, bad error
connect /pipeline/main/no to /connector/console/in;
end;
# Deploy the flow so tremor starts it
deploy flow main;
This error focused on the fact that the output did not exist, so to fix the error, I wrote a separate function that checked whether the output existed, then connected it to the ConnectInput structs while sending an error statement and a status report to the system. This process introduced me to focusing on small incremental steps rather than solving the problem as a whole and allowed me to not get overwhelmed. Additionally, outputs had to be added to the Executable Graph struct, which led me to implementing outputs in related functions and building a hashmap for the representation of its graph. With that, the basic problem of catching the errors was solved for that error problem.
After that led to defining what the error was, which involved adding a port struct to both ConnectInput and ConnectOutput to connect inputs. This port struct wasn’t needed before but with changes that were made later on, port proved to be very useful in defining what the port was to be able to be used in other code. Because this field was added to the struct, changes then had to be made to all the functions that used this struct and a port had to be defined in those functions.
Last was implementing where the code was to the user. This focused heavily on adding transmitters and receivers to output the status and mapping the status when the user’s code had errors. The transmitters and receivers, tx and rx had to be added to the ConnectInput and ConnectOutput structs, then weaved together with the other types of code to be defined and used. This involved many functions to be modified in order to return a result. In this process, there were also bugs to be fixed in the preexisting code and tests that had to be corrected in order to make sure tx and rx were properly working. Afterwards, Result::map_err was used in order to map out the results with its parameters through rx if a user inputted errors.
Throughout the programming, I had to search for the files to determine where the code was and what function utilized the next function. This led me to search into files to see where the error travels through and trace where the error goes as I searched through the declarations, definitions, and references of variables and functions. I also got to learn several handy keyboard shortcuts throughout this process as demonstrated from my mentor.
Conclusion
Overall, working with Tremor was extremely fun and valuable as I not only got to contribute to an incredible project, but also got to learn more about programming and the open-source world. I was able to while meeting amazing people to guide me with my work, and I can not imagine it to be any other way.